Sulautettua ohjelmaa kirjoittaessa toimitaan tavallisesti hyvin lähellä rautatasoa ja usein myös ohjelma- sekä käyttömuisti ovat hyvin rajallisia. Toimintaympäristö on siis hyvin erilainen kuin esimerkiksi tavallisessa pc-ympäristössä. Tässä artikkelissa käsitelläänkin joitain sulautetun ohjelmoinnin erityispiirteitä sekä hyviä käytäntöjä, C-kielen näkökulmasta. Artikkelissa ei käydä läpi C-kielen perusteita, eli ainakin perussyntaksin olisi hyvä olla jo tuttua.
Artikkelista tuli melko pitkä, mutta se on jaettu itsenäisiin osiin, jotka voi lukea (tai jättää lukematta  ) haluamassaan järjestyksessä.
) haluamassaan järjestyksessä.
Moduulijako
Ensimmäiseksi käsitellään aihetta, joka on hyvin tärkeä kaikessa ohjelmoinissa, nimittäin koodin jäsentäminen selkeästi. Ohjelma kannattaakin jakaa selkeisiin osiin (moduuleihin), joista kukin toteuttaa jonkin selkeän kokonaisuuden. Tällöin ohjelmakoodin lukeminen helpottuu ja jo kertaalleen toteutettuja ja testattuja moduuleita voi käyttää uudelleen. C-kielessä moduulijako tapahtuu tiedostojen avulla. Moduulin rajapinta sijoitetaan otsikkotiedostoon (.h päätteinen) ja varsinainen toteutus lähdekooditiedostoon (.c päätteinen). Moduulin voidaan ajatella olevan musta laatikko, joka tarjoaa rajapinnan kuvaamat toiminnot. Käyttäjän ei siis tarvitse välttämättä tietää/muistaa miten toiminnot on toteutettu. Seuraavana esimerkki moduulista
motor.h
// Tämä on esiprosessorikäsky, joka estää saman tiedoston
// useampikertaisen includoinnin
#ifndef MOTOR
#define MOTOR
// Funktio käynnistää moottorin funktion "motor_set_speed" asettamaan
// nopeuteen. Jos nopeutta ei ole asetettu, on se oletuksena 100%.
void motor_start();
// Funktio sammuttaa moottorin
void motor_stop();
// Funktio asettaa moottorinohjauksen PWM-työjakson 0-100%.
// Parametrin arvot, jotka ovat yli 100, tulkitaan sadaksi prosentiksi.
void motor_set_speed(unsigned char speed);
#endifmotor.c
#include "motor.h"
void motor_start()
{
// Toteutus...
}
void motor_stop()
{
// Toteutus...
}
void motor_set_speed(unsigned char speed)
{
// Toteutus...
}Moduulia käytettäisiin siten, että esimerkiksi pääohjelmaan (main.c) lisätään alkuun #include “motor.h”, jonka jälkeen rajapinnassa esiteltyjä funktioita voi käyttää normaalisti. Rajapinnassa voi esitellä myös vakioita, makroja, ym. Huom. Jos motor.c tiedostoon määritellään funktioita, vakioita, tms., joita ei ole rajapinnassa, niin niitä ei voi käyttää motor.c:n ulkopuolelta. Näitä kutsutaan moduulin yksityiseksi rajapinnaksi.
Perustietotyyppien koot
Sulautettujen järjestelmien ohjelmoinnissa on usein tarvetta lukea tai kirjoittaa tietynlevyinen rekisteri. Rekisterin koko selviää kontrollerin/prosessorin datalehdestä, mutta minkätyyppiseen muuttujaan arvo tulisi tallentaa? ANSI C standardi määrittelee esimerkiksi int-tyyppien koot hyvin väljästi: “short int <= int <= long int.” Kannattaa siis pitää mielessä, että tietotyyppien koossa voi olla kääntäjä- ja alustakohtaisia eroja. Ainakaan ei kannata tehdä perusteettomia oletuksia, vaan on parempi tarkistaa asia kääntäjän dokumenteista. Monille kääntäjille on myös tehty valmiit typedef määrittelyt, joilla muuttujien koot on helppo saada oikeiksi.
// Monille kääntäjille löytyy valmiit typedef-määrittelyt perustietotyypeille
// stdint.h tiedostosta
#include <stdint.h>
// typedef:n avulla voidaan antaa tietotyypille uusi nimi:
// huom. Nimen perään lisätään usein _t, joka kertoo, että kyseessä
// on typedef eikä natiivi tyyppi.
typedef unsigned char my_uint8_t;
int main()
{
// Kuten nimestä selviää, kyseessä 8-bittinen etumerkitön kokonaisluku.
uint8_t x = 0;
// sama kuin: unsigned char y = 1;
my_uint8_t y = 1;
}Vakiot ja makrot
Vakioiden sekä makrojen avulla voidaan parantaa ohjelmakoodin luettavuutta sekä helpottaa muutosten tekemistä huomattavasti. Makrojen avulla voidaan myös helpottaa koodin siirtämistä toiselle kontrollerille, kun kontrollerispesifiset asiat, kuten käytetyt pinnit, määritellään makrojen avulla. Katsotaan ensin, miten vakioita voidaan määritellä.
// Vakio varatun sanan const avulla
const unsigned char maksiminopeus = 100;
// Vakio makron avulla
#define MINIMINOPEUS 10Näiden kahden tavan erona on se, että ensimmäisessä tapauksessa luodaan muuttuja, jonka arvoa ei vain voi muuttaa. Tällöin vakio käyttää yleensä datamuistia, joka on usein hyvin rajallinen. Definellä määritelty vakio sen sijaan toimii siten, että esiprosessori korvaa kaikki MINIMINOPEUS merkkijonot luvulla 10, ennen koodin käännöstä. Lopullisessa ohjelmassa ei siis varata muuttujaa, vaan arvo 10 on ohjelmakoodissa literaalina. Definellä määriteltynä vakio siis monistuu koodiin ja kasvattaa ohjelman kokoa. Kolmas mahdollisuus on käyttää const-vakioita ja käskeä kääntäjää sijoittamaan muuttuja nimenomaan ohjelmamuistiin.
Vakion määrittely ohjelmamuistiin AVR:llä.
#include <avr/pgmspace.h>
const char kehote[] PROGMEM = "Syötä komento: ";Vakion määrittely ohjelmamuistiin PIC:llä.
rom const char kehote[] = "Syötä komento: ";Seuraavaksi katsotaan, mitä muuta definellä voisi tehdä.
// Ledin käyttämä portti PIC-kontrollerilla
#define LED_SUUNTA TRISGbits.TRISG0
#define LED_POWER PORTGbits.RG0
// Käyttäjäkomennot
#define KOMENTO_RUN 'r'
#define KOMENTO_STOP 's'Nyt led voidaan sytyttää koodissa komennolla “LED_POWER = 1;”, joka on itsessään hyvin kuvaava eikä vaadi juuri kommentointia. Lisäksi jos ledi halutaan vaihtaa toiseen pinniin, niin ainoastaan defineä tarvitsee muuttaa. Makrojen avulla voi tehdä myös yksinkertaista funktiota muistuttavia toimintoja, mutta ne on jätetty tästä pois, sillä niillä on turhan helppo ampua itseään jalkaan. 
Katsotaan kuitenkin miten makrot voisivat toimia testauksen apuna.
// Kommentoi/poista tämä rivi, kun testitulosteita ei haluta
#define TESTAUS
// koodia...
// Testituloste, joka sisällytetään ohjelmaan, vain silloin, kun
// TESTAUS makro on määritelty
#ifdef TESTAUS
printf("Tämä on testituloste\n\r");
#endifMuistin käyttö
Kuten aikaisemmin jo todettiin, niin sulautetuissa järjestelmissä käyttömuistia on usein hyvin rajallinen määrä (erityisesti pienissä mikrokontrollereissa), joten sen käyttöön kannattaa kiinnittää erityistä huomiota. Mikrokontrollereita ohjelmoitaessa kannattaakin siis välttää dynaamista muistinvarausta, syviä aliohjelmakutsupuita sekä rekursioita (funktio joka kutsuu itseään).
Dynaamisella muistinvarauksella tarkoitetaan C-kielen new-operaattorilla ajonaikana varattavaa muistia. Kaikista pienimmissä kontrollereissa dynaaminen muistin varaaminen ei välttämättä ole edes mahdollista. Aliohjelmakutsupuulla tarkoitetaan rakennetta, joka kuvaa eri funktioiden välisen kutsuhierarkian. Eli mitä useampi funktio kutsuu aina uutta funktiota, sitä syvempi puu muodostuu. Tästä voi seurata ongelmia, koska jokaisella funktiokutsulla pitää varata muistista tilaa paluuosoitteelle, parametreille sekä paikallisille muuttujille. Tällöin on riskinä, että muisti loppuu ja juuri tästä syystä myös rekursiota tulisi välttää. Näiden ongelmien ymmärtämiseksi tarkastellaan seuraavaksi pinoa.
Pino (stack) on LIFO (last in first out) muistirakenne, jota käytetään funktiokutsun parametrien, paikallisten muuttujien sekä paluuosoitteen talletukseen. LIFO-rakenne tarkoittaa sitä, että viimeiseksi lisätty alkio saadaan ensimmäisenä ulos. Seuraava kuva selventää pinon toimintaa funktiokutsussa.
Periaatekuva pinon toiminnasta (pinon rakenne vaihtelee eri prosessoreilla).
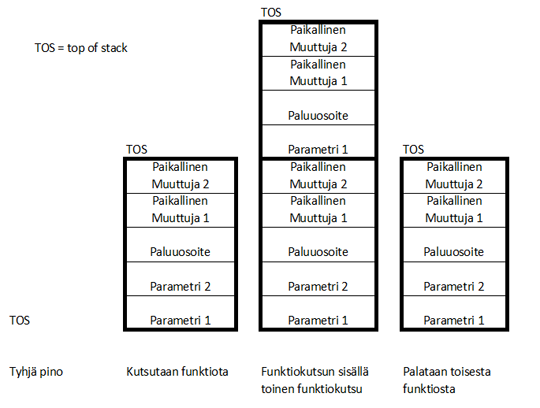
Huomataan, että kun funktiokutsun sisällä on toinen funktiokutsu, niin pinon koko kasvaa nopeasti ja muisti vapautuu vasta, kun ohjelma palaa funktiosta. Huomataan myös, että parametrien määrä ja koko vaikuttavat pinon koon kasvuun. Tästä syystä funktiolle ei kannata koskaan välittää suuria parametrejä, vaan kannattaa käyttää osoittimia. Pinon kokoon vaikuttavat myös paikalliset muuttujat, joten sulautetuissa järjestelmissä on täysin perusteltua käyttää globaaleja muuttujia.
C-kääntäjä huolehtii pino-operaatioista automaattisesti, mutta siitä huolimatta on hyvä ymmärtää ainakin periaattellisella tasolla, miten pino toimii ja mitkä asiat vaikuttavat sen kokoon.
Kääntäjän kirjastot
Viimeisenä aiheena käsitellään lyhyesti kääntäjän kirjastoja. Tässä kappaleessa ei varsinaisesti käydä läpi minkään tietyn mikrokontrollerin kirjastoja, vaan lähinnä muistutetaan, että kaikkea ei aina tarvitse/kannata tehdä itse. Toki opiskelun kannalta on hyvä tehdä asiat alusta asti itse, mutta muuten voi olla hyödyllistä käyttää valmista koodia. Monille mikrokontrollereille löytyy valmista koodia esimerkiksi sarjaportin, i2c-väylän, ajastimien, viiveiden, ym. käyttämiseen. Seuraavana lyhyt esimerkki kuinka kääntäjän kirjastot voisivat helpottaa elämää sekä linkit AVR:n sekä PIC:n kirjastoihin, joista asiaa voi lähteä tutkimaan eteenpäin.
// Tarvittavat kirjastot
#include <usart.h>
#include <stdio.h>
// koodia...
// Sarjaportin alustus ja tulostus
OpenUSART1( USART_TX_INT_OFF &
USART_RX_INT_OFF &
USART_ASYNCH_MODE &
USART_EIGHT_BIT &
USART_CONT_RX &
USART_BRGH_HIGH,
25 );
printf("Tulostus sarjaporttiin\n\r");PIC C18 kääntäjän kirjastot:
http://ww1.microchip.com/downloads/en/devicedoc/MPLAB_C18_Libraries_51297f.pdf
AVR-LIB kirjastot:
http://www.nongnu.org/avr-libc/user-manual/modules.html
 Voisin kuitenkin väittää tähän vastaan, koska debuggerilla nähdään flashin ja rammin sisältö ja se auttaa joskus todella paljon esim. jos pointtereiden kanssa on ongelmia tms joita ei ilman lisäkikkailuja saa selville. Lisäksi taulukoiden läpi käymistä voidaan suorittaa rivi-riviltä tai solu-solulta (miten sen nyt haluaa sanoa) yms hyödyllistä. Vieläpä: debuggerilla voidaan testata peripheraaleja (ADC, UART/USART jne) suoraan kirjoittamalla arvoja rekistereihin jolloin myös ympärillä olevaa rautaa voidaan testata step-by-step menetelmällä.
Voisin kuitenkin väittää tähän vastaan, koska debuggerilla nähdään flashin ja rammin sisältö ja se auttaa joskus todella paljon esim. jos pointtereiden kanssa on ongelmia tms joita ei ilman lisäkikkailuja saa selville. Lisäksi taulukoiden läpi käymistä voidaan suorittaa rivi-riviltä tai solu-solulta (miten sen nyt haluaa sanoa) yms hyödyllistä. Vieläpä: debuggerilla voidaan testata peripheraaleja (ADC, UART/USART jne) suoraan kirjoittamalla arvoja rekistereihin jolloin myös ympärillä olevaa rautaa voidaan testata step-by-step menetelmällä.