I already had my Raspberry Pi up and running with ruuvi-collector and an on-pi Influx database and Grafana when the SD card got corrupted and I had to start over.
The second time I decided to document the process of setting the Raspberry up the way I wanted, would this ever happen again. And while I was at it I decided to transmit the data to AWS to be able to view it online.
This exercise resulted in a Terraform project that sets everything up in AWS by the click of a button (more or less).
If it may help anyone, it’s available here
And as with any GitHub project, improvement ideas and especially PRs are welcome
@Motobiman The ruuvi-collector java program transmits the data collected from the ruuvi-tags straight to the InfluxDb in AWS. The URL must be set up in ruuvi-collector.properties and in the AWS setup I’ve exposed the InfluxDb port to the Internet (password protected and over HTTPs, though).
Over WiFi. Raspberries don’t have cellular connectivity AFAK. But I’ll eventually place the tags at a location where the connection between the wifi router and the internet is going over a cellular 4G connection. But that has nothing to do with this setup, really.
You can use a 3G/4G modem with built-in WiFi? Of course you’d still need the Raspberry Pi in between to receive the Bluetooth data and forward it over WiFi.
what happens in a scenario where the internet is down for a few hours? ie. RPi connected to Wifi router, Wifi router connected to Internet via 4G just how you want to use it in the future.
What is the reason for the load balancer on the AWS side? Couldn’t you just use the URL of the EC2 instance directly?
Undoubtedly the data would be lost when the 4G connection is down. Some local buffering on the RPi would be a great addition to this setup.
The load balancer is mainly for the ease of setting up https connections from the internet through it. That way, I don’t need to configure both InfluxDb and Grafana with certificates, a hassle of its own. Instead I can easily issue a certificate in AWS and connect it to the load balancer and then let the traffic between the load balancer and the ec2 instance go unsecured over http.
Yep but you cant have the BT, wifi and 3/4g connected at the same time and the Rpi struggles to process the data from many tags anyway.
I still envisage the Rpi doing just the data collection over BT at predetermined times (no need for wifi at all) and squirting the raw packets over 3/4g at other times, to be processed at the receiving end, where power and crunching capacity is pretty much unlimited.
I have the older RPi without built-in WiFi or Bluetooth (Model B rev 2 I believe), so I have two dongles connected to it for that. I only have three tags, but if they are close enough I haven’t experienced any data loss or processing problems on the pi, despite the old model, the dongles and running Ruuvi-collector which crunches the data before sending it to the DB in AWS. But sure, with more tags I guess the ceiling will be reached at some point.
But wait, how would you get 3g/4g connectivity to the pi? And if you have that, why would you need WiFi at all then?
And besides, sending the raw tag data to an iot processing endpoint instead of processing it in the pi shouldn’t be a problem I suppose? I saw another project here in the forum that did something with the AWS iot service.
That set up would likely not be viable with battery/solar.
The Rpi with a 3/4g hat has apparently the lower power draw that I need (but I have all but given up on the setup) or 3/4g dongle that is apparently connecting but not working yet on Hologram.
Just seems more efficient to do the processing on a mac or pc rather than on a much slower Rpi and with M2M and raw data should be cheaper too.
AWS pricing needs a degree in mathmatics to work out and Amazon are wealthy enough already without my money.
The amount of data coming from RuuviTags is so little that it’s trivial to do the initial crunching anywhere (converting the raw data to a more human friendly format, ie. temperature into a decimal number in celcius, rather than an integer describing one 200th of a celcius), and thus it makes sense to do this as early in the “pipeline” as possible, and leave the “heavier crunching” like computing averages and trends over a longer time period to later stages. Though it shouldn’t be an issue to process the data later, as mentioned. I guess it all depends on the desired setup.
The 2.4Ghz radio frequencies for Bluetooth will be overly saturated far before a RPi runs out of processing capacity for the initial processing in the collector. A synthetic benchmark earlier in RuuviCollector development showed the capacity to process around 20 000 measurements per second on a RPi3b, and far exceeding 100 000 measurements per second capacity on my PC. (the benchmark was done from a dummy datasource generating fake hcidump output as fast as possible and the collector parsing it as normal). Not being a bottleneck was one of the original design criterias for RuuviCollector development, and it turned out to be trivial to accomplish.
Another design criteria for RuuviCollector was to have a relatively standard and easy way to “decouple” the collection process from everything else, ie. have the collector running on a RPi somewhere in the corner and everything else on a real server (or everything just on the RPi itself). It’s nice to see a well documented and implemented setup of this “decoupling”, nice work there @bostrom I’m planning on adding a small “example setups” section to the RuuviCollector repo, I hope you don’t mind if I link to your setup from there
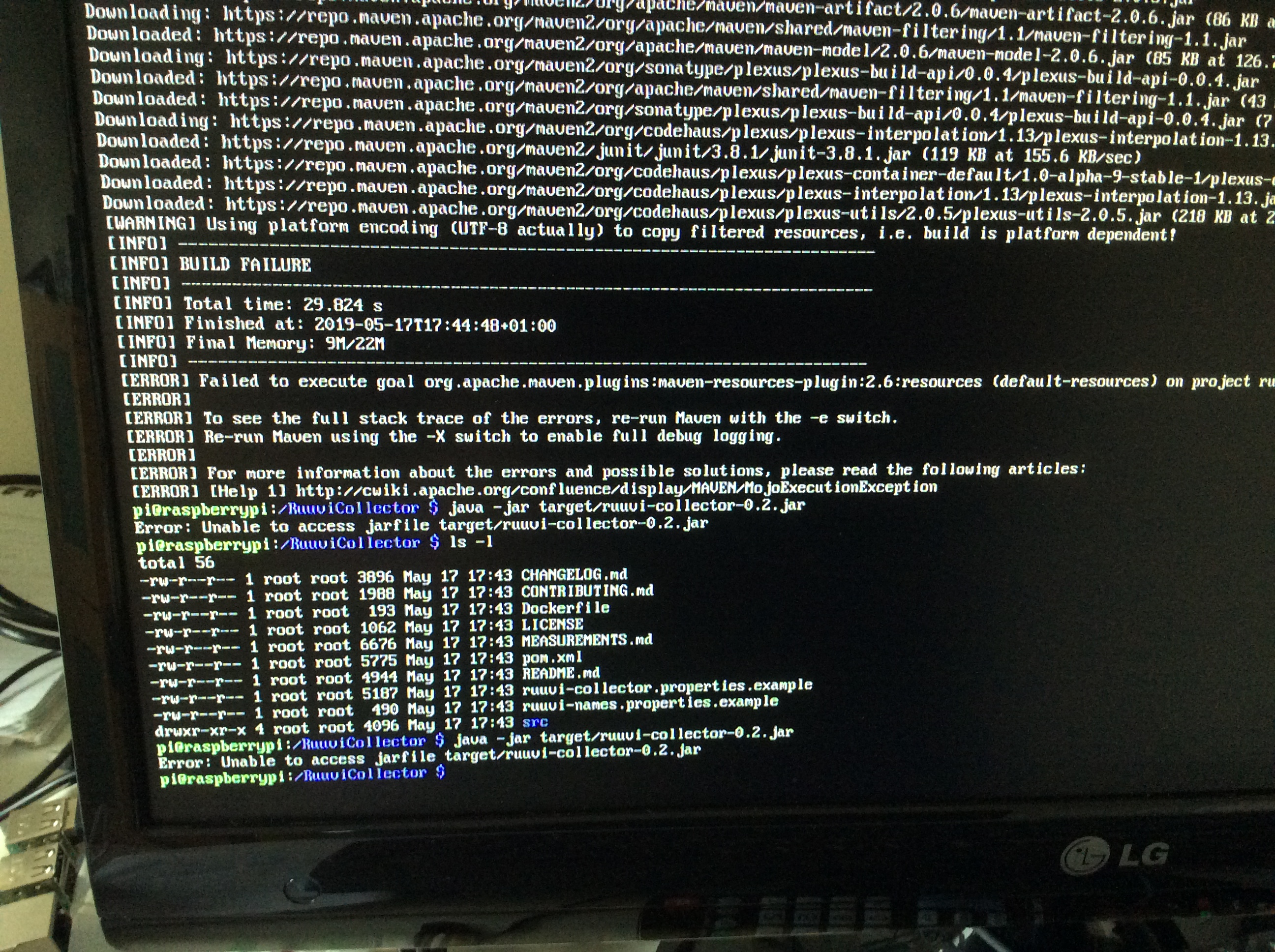
It looks like you have the repository cloned into /RuuviCollector/ with everything owned by the root user while you’re running the commands as the pi user. The pi user doesn’t have write permission anywhere in that directory so the build fails, as the permissions only allows the owner to write. You can fix that by issuing the command:
sudo chown -R pi /RuuviCollector
which will recursively change the ownership of /RuuviCollector/ and eveything inside it to the pi user.
After that you should be able to build the package as the pi user


 I’m planning on adding a small “example setups” section to the RuuviCollector repo, I hope you don’t mind if I link to your setup from there
I’m planning on adding a small “example setups” section to the RuuviCollector repo, I hope you don’t mind if I link to your setup from there